Navigating Big Data Projects: From DB2 to Hive with Spark
Introduction
In this blog, we delve into a fascinating data migration and transformation project I worked on, transitioning data from a DB2 database to Hadoop/Hive using Spark. This journey is not only technical but also tailored to a diverse audience, from freshers and recent graduates to seasoned professionals. Let’s explore the architecture, challenges, and best practices that made this project a success.
The Project Overview
Data Source: DB2 Database
Our project started with a DB2 database, a robust RDBMS, housing various pieces of customer, credit card, offer, and product information. The client required a monthly report, addressing questions such as:
- How many credit cards were offered to customers last month?
- How many customers were actually presented with an offer?
- How many of those customers used the offer to make a purchase?
Identifying Source Tables
The data needed for the report wasn’t contained in a single table but spread across several:
- Customer Information
- Credit Card Details
- Offer Information
- Product Details
As a data engineer, my task was to identify these tables and craft SQL queries to extract the necessary data. This multi-table querying was crucial for compiling a comprehensive report.
Data Migration and Transformation
Using Sqoop for Data Migration
Instead of performing transformations within the DB2 database, we opted to use Sqoop to migrate the data to Hadoop/Hive. This approach facilitated storing the data in Hive tables, which we then queried to generate the report. Automation was key here; we scheduled the migration and transformation to run monthly, ensuring the report was ready by the 5th of each month.
Hive vs Spark: Evolution in Big Data
From Hive to Spark
Around 2015–2016, Hive was the go-to tool for big data projects. It provided a SQL interface for querying Hadoop data, making it accessible for SQL developers who didn’t need to learn Hadoop. Hive’s role was pivotal, and without it, many big data projects wouldn’t have materialized.
Spark’s Emergence
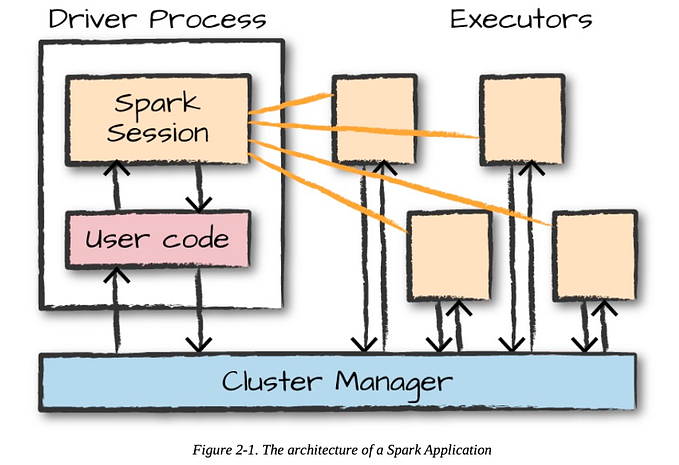
By mid-2016, Spark started gaining traction alongside Hive. Initially, Hive handled all transformations, but Spark’s capabilities soon revolutionized the ETL process. Spark’s performance improvements, particularly with DataFrames and Datasets, made it the preferred choice for transformations, while Hive continued to excel at data storage and querying.
Implementing the Transition
Integrating Spark with Hive
We transitioned from using Hive for all ETL tasks to leveraging Spark specifically for transformations. This shift was driven by Spark’s superior performance and flexibility. Here’s how we made the switch:
- Initially, Hive was used for both storage and transformations.
- Spark was introduced as a proof-of-concept (POC) and later became the cornerstone of our transformation pipeline.
Spark’s Capabilities and Performance
Comparing RDDs, DataFrames, and Datasets
Spark’s journey from RDDs to DataFrames and Datasets significantly enhanced performance. DataFrames and Datasets, built on the Catalyst optimizer, provide a high-level API for data manipulation, making Spark much faster than traditional MapReduce and even Hive.
Optimizing Data Processing
Spark’s integration with Hive allowed us to read data from Hive tables, avoiding the cost and complexity of direct DB2 queries. This setup was not only cost-effective but also optimized for the big data ecosystem, ensuring seamless data flow and transformation.
The ETL Process and Deployment
Data Loading and Reporting
Our ETL pipeline involved:
- Data Storage: Source data was stored in a Hive database, while the transformed report was saved in a target Hive table.
- Scheduling: We used tools like Autosys, Control-M, or Airflow to automate job execution. This setup ensured that our reports were generated on schedule without manual intervention.
Deploying Spark Jobs
Deploying Spark jobs involved:
- Creating a JAR file for the Spark transformation logic.
- Using shell scripts to execute the job, placing the scripts and JAR files in the cluster.
- Ensuring the job was scheduled correctly in all environments — local, dev, UAT, and production — with distinct configurations for each.
Monitoring and Quality Assurance
Job Execution and Status Checking
The Autosys scheduler triggered our Spark job via a shell script. Post-execution, we checked the Hive table to confirm data integrity and completeness. The scheduler’s UI or logs provided insights into job status, helping us quickly identify and resolve any issues.
Data Quality Checks
We emphasized checking for null values and data consistency at every stage:
- Source Data Check: Ensured DB2 data was clean before migration.
- Migration Verification: Confirmed that data in Hive matched the source, addressing any discrepancies promptly.
Finalizing the Project
Delivering Data to Downstream Teams
The final step involved delivering the transformed data to the downstream team:
- Non-Technical Teams: Provided reports in file formats for direct use.
- Technical Teams: Delivered data in Hive tables, ready for further processing or integration with visualization tools like MicroStrategy or Tableau.
Feedback Loop
We maintained open communication with the downstream team, swiftly addressing any data quality issues they identified. This feedback loop was crucial for maintaining the integrity and utility of the data.
Conclusion
This project was a comprehensive journey through the intricacies of big data, showcasing the evolution from Hive to Spark and the seamless integration of data transformation and reporting. Whether you’re a fresher looking to understand the basics or a seasoned professional aiming to refine your project articulation, this walkthrough provides valuable insights and practical tips for your next big data endeavor.